
Recently Version 7.28 is released, fixed inconsistencies in UTF-8 encoding by the service client issue, this is the reason to suspect the method wwJsonSerializer.deSerialize have same issue, my testing coding as below (server side):
FUNCTION testUTF8
Sys(3101,65001) &&UTF8
p_filename = "C:\temp\testutf8.json"
lcUTF8= filetostr(p_filename )
loSer = CREATEOBJECT("wwJsonSerializer")
loResult = loSer.DeserializeJson(lcUTF8)
RELEASE loSer
RETURN loResult
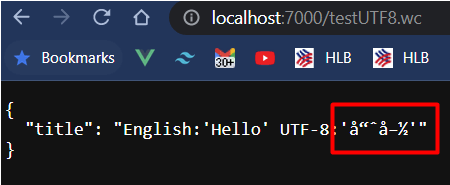
Raw Data:
{"title": "English:'Hello' UTF-8:'??'"}
View Result :
Best Regards
Eddie Tan


JSON serialization has nothing to do with text encoding. The encoding has to be fixed up before you deserialize (or after in the resulting object). It's a transport issue not the job of the serializer.
IOW - apply UTF-8 decoding to your string before you deserialize.
If you're getting the data from a server with the wwHttp it should automatically UTF-8 decode by default (newer versions) which is determined by the wwHttp.lDecodeUtf8 property and a proper UTF-8 encoding header in the HTTP response (ie. content-type: application/json; charset=utf-8).
Otherwise you have to manually apply STRCONV(lcJson,11).
In your example the more likely problem is that you're reading the value from a UTF-8 encoded file and not decoding it so it gets passed right through effectively double encoding. You should print the string you retrieve to screen to see what the actual value of the file is. If you're seeing ?? that means your code page can't handle the retrieved characters.
+++ Rick ---